
Fase Final
Planet de proyectos.

Patrocinio
¿Quieres Patrocinar?
Consulta nuestro Dossier de Patrocinio
Patrocinador Principal

Patrocinador Plata

Patrocinador Bronce







Medios Oficiales




Planet
26 Septiembre, 2010
Introducción a Hping
IntroducciónHping es una herramienta encargada de generar y analizar paquetes TCP/IP, permitiéndonosfalsificar la información enviada con el objetivo de realizar auditorías de seguridady poder testear redes y sistemas de detección de intrusos.Para más información[wikipedia]Para poder utilizarla, suponiendo que estamos en una distribución Ubuntu, desde terminal:sudo apt-get install hping3Un paseo rápida por las páginas de man nos revela que podemos usarla para:
- Probar reglas de firewall.
- Escaneo de puertos avanzados.
- Probar el rendimiento de una red utilizando diferentes protocolos, tamaños de paquetes, tipos de servicios y fragmentación.
- Descubrir la unidad máxima de transferencia (MTU) de un paquete.
- Transferir ficheros a través de un firewall.
- Hacer traceroute entre diferentes protocolos.
- Usarlo como Firewalk.
- Fingerprinting de sistemas remotos.
- Auditar pila TCP/IP.
- ...
UtilizaciónEl uso más sencillo es sustituir a la herramienta ping: La única diferencia está en algunos flags de control, en este caso RA hace referencia a RST/ACK que nos informa de que el puerto está cerrado.Probamos haciendo uso de otro puerto: En este caso observamos como el flag está marcado a SA, lo cual hace referencia a SYN/ACK o lo que es lo mismo, nos está informando de que el puerto se encuentra abierto.Otro uso que podemos darle a hping es emplearlo como el comando traceroute, y que nos muestre el camino que recorre un paquete desde su origen hasta el destino. Configurando los flags a nuestro antojo, en este caso podemos lanzar el comando con la opción -t donde especificamos el valor del TTL(time to live), y con -z que a cada pulsación de CNTRL+z incrementamos en uno el valor del TTL.Otras posibilidades pueden ser:
- Hacer escaneos de puertos del 100 al 110:hping3 seguesec.blogspot.com -V --scan 100-110
- Enviar paquetes UDP spoofeados desde varios destinos:hping3 seguesec.blogspot.com --udp --rand-source
- Firmar paquetes:hping3 -2 -p 7 seguesec.blogspot.com -d 70 -E text.txt
- Enviar paquetes ICMP a un determinado hosthping3 seguesec.blogspot.com --icmp -V
- Enviar paquetes TCP SYM cada determinados segundos a un puerto específicohping3 seguesec.blogspot.com -S -V -p puerto -i segundos
- Y si quieres empezar a tocar las narices provocar un SYN Flood Attack con el siguiente comando:
hping3 -i ul -S -p 80 192.168.0.10
Otras opciones más interesantes pasan por hacer packet crafting o probar las reglas del firewall, que veremos en entradas posteriores.
26 Septiembre, 2010
Introducción a JavaDiKt: qué es JavaDiKt
Terminada la serie sobre la problemática de los kanjis, el lector sabrá a estas alturas lo que es un Kanji, los problemas que genera su búsqueda y la cantidad de información distinta a la que uno puede estar relacionado. Con ésta información podremos explicar al fin qué es JavaDiKt y que objetivos persigue.
Si tuviésemos que hacer una definición estricta de JavaDiKt, ésta sería la siguiente:
JavaDiKt es una aplicación visual libre y multiplataforma para la búsqueda avanzada de palabras e ideogramas japoneses y el estudio tanto de la lengua japonesa como de sus formas de escritura.
Creo que la frase anterior explica de forma bastante genérica cuales son los objetivos del proyecto, si bien deja mucho abierto a la imaginación sobre en que consisten específicamente. Utilizaré las expresiones y palabras subrayadas de la definición para explayarme sobre estos temas:
JavaDiKt será una aplicación visual. Esto significa que la interacción entre el usuario y el programa se hará usando una interfaz gráfica simple e intuitiva.
JavaDiKt será una aplicación libre. El programa en su conjunto estará licenciado bajo GPLv3, y usará librerías libres compatibles con ésta. Así mismo, el entorno de desarrollo usado será OpenJDK, en su implementación totalmente libre IcedTea. Las bases de datos usadas proceden de los proyectos KANJIDICT y JMdict/EDICT de Jim Breen, que usan una licencia propia compatible con la licencia Creative Commons Attribution-ShareAlike 3.0 Unported.
JavaDiKt será una aplicación multiplataforma. Podrá funcionar de la misma manera y con las mismas funciones en distintos sistemas operativos. El programa será desarrollado íntegramente en Java (salvo, quizás, algún módulo de pequeño tamaño), por cual la compatibilidad debería estar garantizada para cualquier sistema operativo. Sin embargo, en un principio solo se realizarán pruebas de compatibilidad y distribuciones para sistemas Windows, Linux y Mac OS.
JavaDiKt está diseñado para la búsqueda avanzada. La gran novedad en el mundo de los diccionarios electrónicos(a mi parecer, claro) será la posibilidad de realizar consultas complejas usando “queries amigables en lenguaje natural”, combinando propiedades características e incluso dibujos. Un ejemplo de ésto sería la query “buscar kanji que tenga 4 trazos y que signifique 「sol」 o signifique「astro」 y que su dibujo se parezca a 「tal」dibujo o se parezca a 「cual」 dibujo”.
JavaDiKt está diseñado para la búsqueda de palabras e ideogramas japoneses. Se pretende a largo plazo que JavaDiKt sea un diccionario tanto de kanjis como de palabras en japonés, de forma que los resultados en una búsqueda, ya sea de kanjis o de palabras, enlacen a definiciones de otros kanjis o palabras. Las primeras versiones se profundizaran, sin embargo, en la búsqueda de kanjis, de forma que las nuevas funcionalidades se irán añadiendo de forma progresiva en nuevas versiones.
JavaDiKt proporcionará herramientas para el estudio tanto de la lengua japonesa como de sus formas de escritura. JavaDiKt pretende ser a largo plazo una herramienta completa para el estudio integro de todos los aspectos de la lengua japonesa. Incluirá herramientas como la generación personalizada de tarjetas de estudio, juegos de aprendizaje, etc…
Y con esto termina la entrada de hoy. La entrada siguiente tratará sobre como se van a conseguir estos objetivos mediante la explicación de la estructura del programa.
25 Septiembre, 2010
Una pequeña idea...
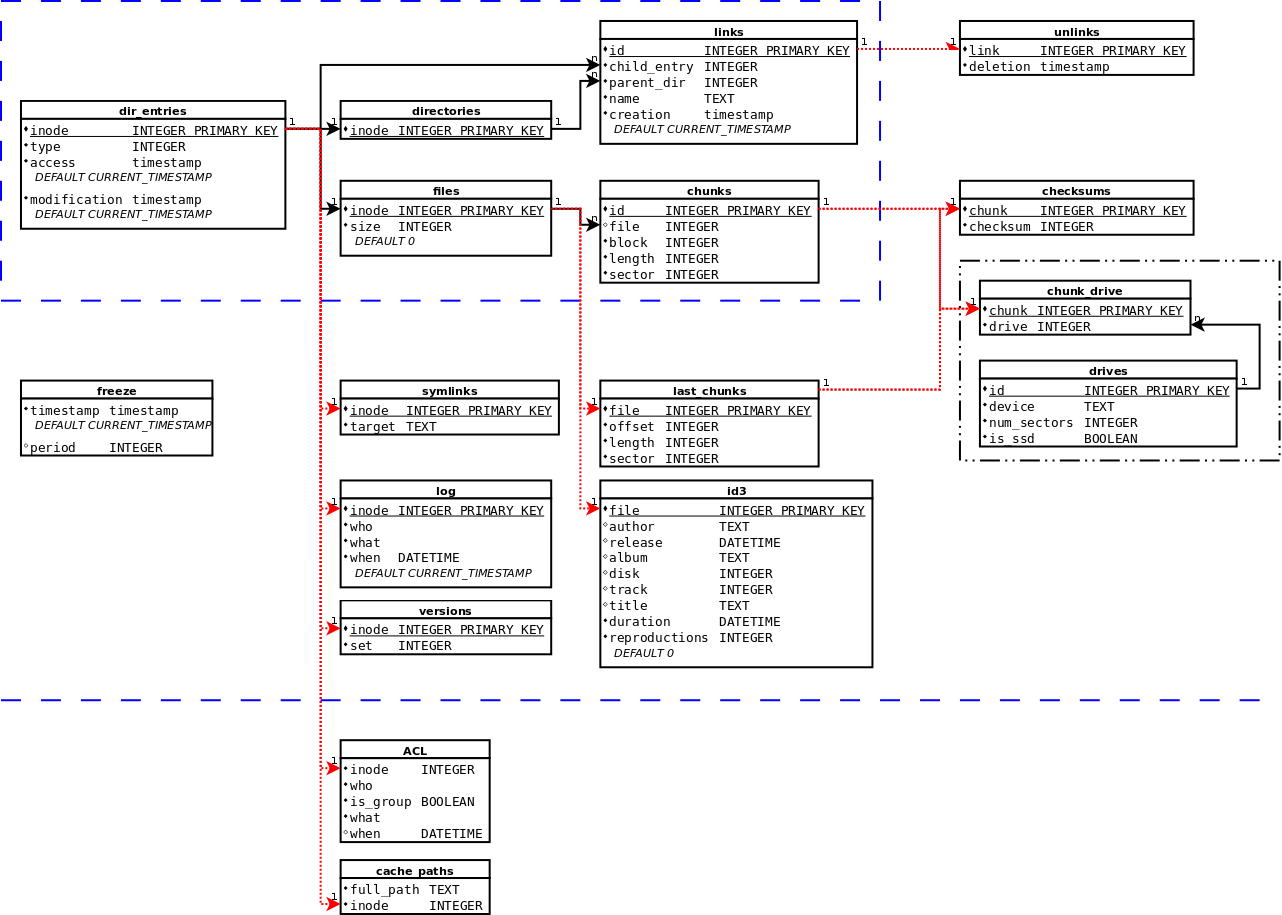
Como puse en mi anterior entrada, PirannaFS empece a hacerlo entre otras razones porque queria experimentar con FUSE. Si, cuando quiero probar una nueva tecnologia no me leo un manual y hago el famoso Hola Mundo, me saco mi propio libro :-P y es por eso por lo que debido a todos los problemas que estoy teniendo para desarrollar PirannaFS y lo escueta, ofuscada y desfasada que es la documentacion que se puede encontrar en la pagina de FUSE por lo que estoy escribiendo mi propio tutorial de desarrollo de sistemas de archivos usando python y FUSE.Mi idea en un principio era utilizar PirannaFS directamente como codigo de ejemplo del tutorial y es por eso por lo que he intentado que el codigo fuese lo mas claro y limpio posible, pero lo cierto es que el proyecto se ha convertido en algo realmente grande y complejo, aparte de por las optimizaciones que le he hecho para la escritura de los archivos como sobretodo por el usar una base de datos (y eso ya si que no es normal) asi que decidi empezar de cero otro sistema de archivos, este ya con mas complejo de Hola Mundo ;-)PyRamFs es un sistema de archivos que usa objetos en memoria para guardar los datos: los archivos son strings y los directorios son diccionarios. Mas simple, imposible :-D Lo bueno del caso es que lo he estado escribiendo en orden de importancia a la hora de realizar un sistema de archivos, y es por eso por lo que empece con los archivos antes que con los directorios con lo que hasta ahora es un sistema de archivos de un unico nivel como el de CP/M y similares. Realmente me esta quedando bastante simple y minimalista, en parte por la simpleza del diseño y en parte porque ya no me pilla de nuevas, y es por eso que pense: si este sistema es tan simple porque (por ahora) no tiene subdirectorios... ¿se podran sacar tambien los subdirectorios del nucleo de PirannaFS para que sea aun mas simple e implementarlos como un modulo externo al igual que ha pasado con los links simbolicos?Asi que nada, me fui al diagrama en el que tengo organizadas las tablas de la base de datos a echar un vistazo :-D(Lo que esta en el recuadro azul son las tablas del core, las que estan alrededor son modulos "de ampliacion" ya que sus primary keys coinciden con las de las tablas del core y amplian su funcionalidad, y las dos tablas de abajo son de modulos auxiliares en los que su primary key no es dependiente de ningun elemento almacenado en el core)Como podeis ver, dentro del core estan bastante separadas las tablas relativas a los directorios de las relativas puramente a los archivos, por lo que si no fuera por el nombre y por la fecha de creacion de la tabla links no seria complicado el sacar los directorios fuera y que el core funcione con un unico directorio aunque sin lugar a dudas donde se complicaria mas el tema seria con las consultas de acceso a los datos, que tendria que volver a cambiarlas (¿otra vez a cambiar la estructura de la base de datos? no, por favor...).Sin embargo, la idea me gusta. No se si sera mejor desarrollarlo tambien como otro modulo externo y que el usuario elija uno u otro, o si ver la posibilidad de sacar los campos de nombre y creacion de la tabla links a una tabla aparte que sea la que se mantuviese dentro de la estructura minima para poder acceder a los archivos, pero en cualquier caso viendo el diagrama me he dado cuenta que aunque no tuviera nombres de archivo tampoco seria mucho problema, ya que si llego a implementar los modulos de metadatos (como el ejemplo que tengo puesto de mp3) se podria acceder directamente a traves de las bibliotecas de musica, fotos o lo que sea puramente a traves de los metadatos y entonces eso si que seria algo revolucionario: un sistema de archivos sin archivos :-PAhora bien, en caso de que llegara a implementarlo, ¿como lo hariais vosotros? ¿que el usuario tenga que decidir entre los dos modulos (un solo nivel o sistema jerarquico), o dividir la tabla links y que el mono-nivel este por defecto? ¿la tabla directories tendria algun sentido entonces (esta puesta para forzar luego en las consultas que links.parent_dir sea efectivamente un directorio valido)? ¿lo tiene ahora?Yo, de momento, ya he alineado dir_entries con files y chunks en el diagrama por si sigo adelante con la idea... ;-)
24 Septiembre, 2010
Descripción de la aplicación
A continuación voy a explicar qué es TP ( o qué pretendo que sea ) y cuál es su utilidad.
El nombre Terminal Previewer dice bastante sobre ella. La idea es solucionar el problema de la previsualización de archivos mientras navegamos por el sistema de ficheros a traves de un terminal de texto. Al hacerlo a través de un navegador, al estilo de Nautilus en Gnome, se utiliza el ratón para moverse por el árbol de directorios y los archivos, y si se configura, pueden ser previsualizados al tiempo que se navega. Sin embargo, en terminales de texto, es necesario abrir una aplicación para poder hacerlo.
Como es evidente, esto conlleva una pérdida de tiempo muy grande a la vez que hace dificultosas tareas de renombrado o clasificación de imágenes, música o documentos.
La interfaz del programa será algo similar a un panel lateral de escritorio, en un principio Gnome, donde se muestren miniaturas de los archivos y se puedan reproducir archivos de audio. La navegación de realizará a través del mismo terminal utilizado habitualmente. Para ello, se ejecutará una subshell que procese todos los comandos disponibles en el terminal, tal y como si TP no se hubiera ejecutado. En tiempo real, se actualizará el contenido del panel y se permitirá abrir los archivos para verlos en tamaño real o en el programa por defecto utilizando el ratón o atajos de teclado. De esta manera, la utilización del ratón se reduce al mínimo y se reduce el tiempo perdido.
Tal y como he mencionado, la aplicación estará en un principio disponible para terminal y escritorio Gnome, si bien estudiaré en un futuro la posibilidad de realizar una interfaz para Kde o Xfce.
24 Septiembre, 2010
Bienvenida
Bienvenido al blog dedicado al desarrollo del proyecto TP – Terminal Previewer. En los próximos meses se recogerá en esta bitácora todo lo que acontezca relacionado con el diseño y la implementación del proyecto. Proximamente os contaré en qué consiste exactamente y los objetivos que pretendo marcar.
23 Septiembre, 2010
Intenciones en el desarrollo
Solamente me gustaría comentar cómo pretendo ir desarrollando el proyecto.
A grandes rasgos, os hago una lista cronológica para que sepáis más o menos como pienso ir desarrollandolo:
- Diseño del proyecto. Generación de diagramas UML con todas las características.
- Implementación. Será progesiva y puede verse parada para documentarme sobre los aspectos que haga falta.
- Documentación. Aunque lo ponga en un punto distinto, procuraré ir generándola a medida que avance el proyecto.
- Sacar versión.
- Revisión / adición de características. Como pensync no es un proyecto cerrado, estoy abierto a sugerencias e ideas nuevas. De momento, implementaré las características que yo he pensado y a partir de éste punto, volveré al 1 con las nuevas ideas y así iré haciendo.
Quiero añadir que igual el avance del proyecto no es regular y que, espero que no suceda, pero podría llegarse a parar. Tened en cuenta que tengo que compaginar el CUSL con la Universidad y con mi trabajo. Así que el tiempo que tenga libre, lo dedicaré al proyecto. Como podéis entender, doy prioridad a las otras dos cosas.
Esto ha sido todo por hoy.
23 Septiembre, 2010
Vale.. ¿pero de qué se trata?
Pues lo dicho, a continuación os detallo los objetivos e intenciones del proyecto Pensync.
Pensync pretenderá permitirte la sincronización de archivos entre N computadores distintos así como también ofrecerá un sistema de backups incrementales. Todo ésto se pretende que funcione evitando al máximo la interacción con el usuario y procurando que sea lo mas usable posible, para que usuarios no expertos puedan usarlo también, sin problemas.
Pongamos un ejemplo práctico de su posible uso, primero planteemos el problema:
Supongamos que disponemos de 2 computadores, uno de sobremesa y otro portátil. En casa, como casi todos, trabajamos con el sobremesa mientras que cuando estamos fuera, usamos el portátil. Te has pasado toda una noche escribiendo un trabajo que llevas bastante tiempo haciendo y ahora te encuentras en X sitio y estás trabajando desde el portátil. Te das cuenta, de que la versión del trabajo que tienes ahí, es antigua. Coges tu pendrive, dónde sabes que guardáste ése trabajo una vez, pero ves que también es una versión antigua. También ves que no tienes internet disponible y por lo tanto no puedes consultar tu dropbox. Ahí tienes un buen problema.
¿Cómo lo hubieras podido evitar?
Pues con Pensync. Si hubieras configurado a pensyc para que sincronizara automáticamente tu carpeta de documentos, dónde se encuentran todos tus trabajos, simplemente, al haber introducido el pendrive en tu sobremesa, él hubiera comprobado que la versión de los archivos que hay en el disco duro del ordenador es más nueva que la del pendrive, y los hubiera actualizado. Entonces, cuando fueras al portátil y hubiéras introducido el pendrive, hubiera visto que la versión que hay en el pendrive es más reciente que la versión del disco duro del portátil y los hubiera actualizado. Así de fácil.
La idea de Pensync surgió de un problema que tuve, muy parecido al que acabo de exponer más arriba. Como todas las ideas, ha ido madurando hasta llegar a plantearme su desarrollo, añadiendo alguna que otra cosa. Uno de esos añadidos pretende ser un sistema de backups incrementales hacia un dispositivo, sea el que sea (siempre y cuando tenga espacio, está claro). También tengo en mente intentar hacer algo parecido al Time Machine de apple, que vaya guardando las distintas versiones de los archivos cuando hace esos backups y que luego sean accesibles. Luego, quizas haya usuarios que necesiten cierta protección en sus archivos a sincronizar, así que también tengo planteado buscar alguna forma de que únicamente él propietario del pendrive (el usuario) pueda sincronizar los archivos y/o navegar por ellos. Pero esto ya lo iré viendo conforme avance el proyecto.
Bueno, creo que con esto ya os podéis hacer una idea de qué va la cosa.
Espero que os guste y, sobretodo, que le encontréis utilidad.
23 Septiembre, 2010
03. Análisis de requisitos
En el siguiente documento he desarrollado el análisis de requisitos de YakiTo. Para ello he seguido el estándar IEEE 830-1998.
22 Septiembre, 2010
Primeras Pruebas SNAIL-DAQ
Este fin de semana estuvimos en el Circuito de Jerez haciendo diversas pruebas del software y la electrónica de SNAIL-DAQ, del equipo MOTESIC de la Universidad de Cádiz.
Los sensores probados fueron:
Temperatura del motor y acelerómetro, usamos una centralita de elaboración propia como se puede ver en la siguiente imagen.
La gráficas obtenidas,de una de las pruebas, mediante el software SNAIL-DAQ, son las siguientes:
Queremos agradecer a los organizadores de Cardoso School, ya que sin ellos esta prueba no hubiese sido posible.
Y a Salvador Pruaño ya que nos ofreció su moto para realizar todas las pruebas.
22 Septiembre, 2010
02. Elección de una metodología de desarrollo
En el siguiente documento explico la metodología de desarrollo que he elegido para YakiTo, así como las razones que me han llevado a dicha elección:
Colabora









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}