
Fase Final
Planet de proyectos.

Patrocinio
¿Quieres Patrocinar?
Consulta nuestro Dossier de Patrocinio
Patrocinador Principal

Patrocinador Plata

Patrocinador Bronce







Medios Oficiales




Planet
2 Noviembre, 2010
Wait a minute, not a Wordpress blog?
This is a genuine html 5 and css 3 static web page generated using Jekyll and hosted at GitHub. Isn’t it cool?
I can just write this post using my favourite text editor, Textmate, and use Git to upload everything to GitHub. Then GitHub automatically parses everything through Jerkyll and voilà, the dish is served!
Big thanks to Tom Preston-Werner for creating Jekyll and Vincent Driessen for design inspiration.
- Jekyll : link
2 Noviembre, 2010
Primera fase: aplicación local
Hace unos días empecé la primera fase de desarrollo del proyecto. En esta fase estoy programando la aplicación local, que será la que permita al usuario modificar el Live CD a partir de los ficheros de configuración descargados.
Por ahora he desarrollado algunos scripts para automatizar el proceso, y 5 módulos de python para realizar las tareas básicas (parsear ficheros de configuración, crear el entorno, modificar el CD, restaurar el sistema y compilar el CD).
La aplicación sólamente funciona desde la linea de comandos, y utiliza un fichero de configuración de ejemplo (config_package_sample.xml), puesto que me ocuparé de generarlos más adelante desde la aplicación web.
No obstante, aunque aún esta verde la aplicación, he decidido subirla como primera revisión al repositorio, como ejemplo de lo que va a ser la aplicación local.
En los próximos días modificaré el programa para recibir los parámetros desde la linea de comandos (por ahora los scripts sí reciben parámetros, pero la aplicación en Python utiliza variables escritas en el código).
Si quieres descargar la aplicación para probarla, mira cómo hacerlo en el apartado “Descargas“. Una vez descargado, para ejecutar el programa, simplemente en una consola teclea:
sudo python yud.py
1 Noviembre, 2010
Ampliación del plazo de inscripción
Como una de los organizadores de CUSL nos ha pedido a los concursantes, hago una breve reseña de la ampliación del plazo de inscripción del concurso:
Nueva ampliación del plazo de inscripción
La organización del premio local de Madrid nos ha solicitado una ampliación del plazo de inscripción para poder darle más difusión al CUSL dentro de su ámbito e intentar así aumentar el número de proyectos inscritos. Después de debatirlo con el resto de organizaciones locales y tomar una decisión conjunta hemos decidido ampliar el plazo hasta el día 15 de Noviembre.
Sin más, saludos a mis lectores, en breve pondré mis avances con el proyecto.
Un saludo!
1 Noviembre, 2010
import blog; print “Hello world!”
No se me ocurre nada mejor que decir hoy, así que con este insulso post queda inaugurado el blog.
(abucheos de fondo)
Está bien.
Este blog narrará las peripecias que se produzcan durante el desarrollo de Sprite Hut, un editor de sprites escrito en python con el objetivo principal de traer de una vez por todas un editor decente para estos menesteres a GNU/Linux.
Y si es posible, hacerle la vida un poco más fácil a los diseñadores y programadores de videojuegos.
Y conquistar el mundo, por supuesto. El tema dominación mundial que no falte.
1 Noviembre, 2010
Preparandome para empezar….
Bueno, estos dias ando liado con la documentación del proyecto.
Por el momento llevo completada la introducción, elicitación de requisitos. Actualmente estoy con el analisis de requisitos.
Por lo que respecta a la implementación, voy a empezar a leerme libros sobre Python ( lenguaje con el que desarrollaré la aplicación ) y Django( framework que utilizaré ), ya que ahora mismo no tengo ningun conocimiento sobre estas tecnologías.
Espero adquirir pronto soltura con las tecnologías que he citado antes y ponerme cuanto antes con la implementación.
1 Noviembre, 2010
Aprendiendo LaTeX…
Como ya dije en el post “Objetivos del proyecto“, en este proyecto me he planteado metas paralelas al propio resultado final del proyecto. Pues bien, ya puedo decir que una de ellas la he conseguido.
Hace unos dias empecé a utilizar LaTeX, y me ha sorprendido gratamente. LaTeX es un sistema de composición de textos, en el que sólo tenemos que preocuparnos del contenido del documento y no de la apariencia, ya que el procesador de texto de LaTeX crea automáticamente la estructura a partir de las etiquetas que incluyamos, lo cual ahorra considerable tiempo a la hora de escribir.
El único “pero” que se le puede poner es que necesitamos compilar el fichero fuente para generar el documento final, y si queremos modificar algo, debemos modificar de nuevo el fichero fuente (.tex) y compilarlo. No obstante, existen multitud de plugins para editores conocidos o editores específicos de LaTeX que permiten compilar en el propio editor.
En mi caso, he optado por un plugin para Gedit llamado “Gedit LaTeX Plugin“, que integra todas las funcionalidades de LaTeX en el propio Gedit.
Así que ya he decidido qué utilizaré para escribir la documentación del proyecto: LaTeX escrito desde mi Gedit.
1 Noviembre, 2010
Game design document
En Sion Tower no quiero perder demasiado tiempo con papeleo pero necesito llevar cierta organización dada la mediana envergadura del proyecto, conozco el valor de la Ingeniería del Software. Debo definir cuantos detalles pueda y conseguir que las mecánicas estén enfocadas a los objetivos que deseo y no otros, que pocas cosas se coloquen por
31 Octubre, 2010
Vectores y niveles
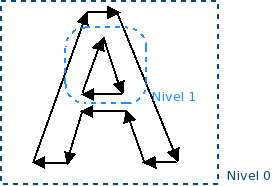
El 90 % de la información que recibimos es percibida a través del sentido de vista. En el caso de Infant este "sentido" también tendrá una gran importancia y por tanto, uno de los factores más importantes será el procesado y tratamiento de las imágenes que reciba. Para ello cada imagen o escena será tratada de modo que los bordes de los objetos serán vectorizados siguiendo el contorno de cada uno de ellos hasta cerrarlo o hasta que quede delimitado. Como un objeto puede tener más detalles en su interior este proceso se repetirá añadiendo niveles de vectores con lo que finalmente lo que Infant verá es el resultado de todo este proceso y será una serie de contornos (representando cada objeto de la escena) con sus respectivos detalles interiores en diferentes niveles de anidamiento (y en lo que he llamado el sistema de coordenadas de objeto pero eso será otro post :P). Un ejemplo más gráfico de esta idea es el que acompaña al post en el que los píxeles que componen los bordes de la letra A son transformados en una secuencia de vectores de diferentes niveles.
31 Octubre, 2010
Repositorio del proyecto.
Ya he creado el repositorio del proyecto, alojado en la forja de RedIRIS (en el siguiente enlace).
En un principio había pensado utilizar git como herramienta de control de versiones por las ventajas que ofrece frente a subversion, pero finalmente he preferido utilizar subversion para el control de versiones, debido a que es lo que utiliza el repositorio de la forja de redIRIS.
Con esta elección simplifico el control de versiones del proyecto, porque no quiero tener que hacer conversiones entre tecnologías (ni usar git-svn). Las herramientas son mecanismos para facilitar el desarrollo de aplicaciones, y en el momento que debemos realizar más operaciones para hacer el mismo trabajo, y no obtenemos con ello beneficios significativos, debemos optar por la tecnología más sencilla.
He creado la estructura básica de subversion (directorios “trunk”, “branches” y “tags”), y ahí es donde iré actualizando el proyecto. Puedes consultar cómo acceder al repositorio para descargar el proyecto en la sección Descargas.
31 Octubre, 2010
Planificación: el paquete data.kanji II, la base de datos Neodatis
En la pasada entrada hablamos sobre el paquete data.kanji e hicimos un esbozo general sobre como estaba organizado. En esta entrada, hablaremos de la base de datos usada para almacenar los datos sobre kanjis, la base de datos de objetos Neodatis, lo cual nos servirá de prólogo para entrar de lleno en las motivaciones de diseño que han dado lugar a la organización actual del paquete data.kanji.
Cuando empecé a pensar en como iba a hacer funcionar todo lo que había pensado para JavaDiKt, lo primero que pensé fue en como almacenar los datos de manera rápida, eficiente y sencilla. Lo primero que consideré fue en recuperar los datos sobre la marcha directamente desde un archivo XML, pero pronto me di cuenta de que el acceso secuencial típico de este tipo de archivos significaba problemas a la hora de hacer búsquedas complejas como las que pretendía.
Después medite la posibilidad de usar alguna base de datos ligera tipo SQL, que pudiese incluirse dentro del mismo programa (es decir, que no necesitase un programa externo). Investigando encontré SQLite, y seguidamente un port para Java. Esta era la solución idónea, pero para mi suponía un hándicap importantísimo, pues si lo que se sé de SQL es poco, lo que sé de modelado de datos SQL es aún menos, eso sin contar la batería de adaptadores y parseadores que tendría que desarrollar.
Estaba ya resignado a tener que empollarme un manual de SQL cuando por casualidad encontré bicheando por Internet algo llamado bases de datos de objetos. Éstas se caracterizan por:
- Permiten almacenar y recuperar objetos de cualquier tipo siempre de manera íntegra, es decir, almacenas un objeto con todos sus atributos y lo recuperas en el mismo estado en el que fue almacenado.
- La base de datos viene modelada según los tipos de clases a las que pertenecen los objetos que están almacenados en ella. Esto quiere decir, por ejemplo, que al almacenar un objeto crearas un nuevo tipo tabla con el nombre de su clase como nombre de la tabla y los atributos de dicha clase como dominios, añadiendo nuevos datos a esa tabla cada vez que añades un objeto de la misma clase.
- Los objetos almacenados en otro objeto como campos o en contenedores formarán tablas nuevas en la base de datos, pudiendo realizar entonces consultas sobre estos objetos sin tener que referirse al objeto que los contenía.
- Cada query solo podrá contener expresiones referentes a un tipo de clase. Esto significa que solo podrá extraerse de la base de datos un tipo de objeto a la vez.
- Cada base de datos es fuertemente dependiente del lenguaje para el que está diseñado y depende en gran medida de las propiedades de éste, como herencia, tipos, genéricos,…etc. Por tanto, las querys son construidas usando métodos, estilos y técnicas propias del lenguaje de programación elegido.
Tengo que decir que me impresionó la sencillez y elegancia del invento, que solucionaba todos mis problemas. De una tacada me ahorraba tanto el modelado de datos usando el mismo modelado de clases del programa, como la construcción de adaptadores recuperando los objetos directamente de la base de datos.
Buscando entonces algo parecido para Java me topé con Neodatis, una base de datos de este estilo y de software libre, con una documentación adecuada y un desarrollo lo suficientemente maduro, y decidí tras una serie de pruebas que era viable su uso.
Además de todo lo dicho anteriormente, Neodatis incluye además algunas características interesantes extras como la posibilidad de construir índices de un campo en concreto de una clase para acelerar las búsquedas de objetos, elaboración de queries muy intuitiva, elección de codificación, exportación/importación XML o una api de desarrollo de constructores de queries.
Sin embargo, Neodatis también presenta algunos problemas importantes.Después de las pruebas, he comprobado que:
- La mezcla de herencia y tipos genéricos en una misma clase genera problemas a la hora de recuperar objetos de dicha clase.
- La única consulta posible sobre contenedores que sean campos de una clase es contains. Esto quiere decir que si, por ejemplo, tenemos una lista de números dentro de un objeto de tipo grupo de números, podremos recuperar todos los objetos de tipo grupo de números que contengan al número 5, pero no a todos los que contengan números menores que 5.
Además para tipos como los mapas ni siquiera esto será posible - Todos los métodos de la base de datos usan técnicas de reflexión y consultas en tiempo de ejecución sobre los tipos de datos, lo que significa que no existe seguridad en los tipos en ningún momento.
- Hasta donde he podido probar, no es posible acceder a la base de datos usando distintos hilos. Solo un proceso puede manejarla a la vez.
- Las consultas sobre igualdad de objetos se basan en la igualdad de atributos entre las dos clases y no en el método
equalsde cada clase.
Y con esto terminamos la entrada de hoy. En la próxima, veremos como todos estos factores han sido fundamentales a la hora de definir la estructura del paquete data.kanji.
Colabora









{kind=link}