
Fase Final
Planet de proyectos.

Patrocinio
¿Quieres Patrocinar?
Consulta nuestro Dossier de Patrocinio
Patrocinador Principal

Patrocinador Plata

Patrocinador Bronce







Medios Oficiales




Planet
4 Octubre, 2010
Proyecto Tablerogo
Hola,
escribimos el primer post comentando de que va nuestro proyecto y cuales son nuestros objetivos.
Nuestro proyecto este año para presentarlo al CUSL tratará de un sistema de deteccion de partidas de go mediante la libreria opencv, ya que las personas de este mundillo necesitan algo asi para subir y guardas las partidas que se juegan en un torneo, en vez de tenerlo que hacer a papel y lapiz, cosa bastante trabajosa. Más adelante tenemos pensado seguir el proyecto y crear un robot que aproveche la detección de una partida para que juegue contra nosotros, con la finalidad de que al jugar por internet, el robot ponga las piedras en un tablero y puedas jugar en tablero contra tu contricante aunque se encuentre en la otra parte del mundo.
Los objetivos de este año serán detectar una partida entera a través de las librerias de opencv y subir una partida a internet mientrs se esté jugando.
Esperamos conseguir nuestro objetivo,
Un saludo y ánimo para todos vuestros proyectos !!
4 Octubre, 2010
Proyecto Brainstorm
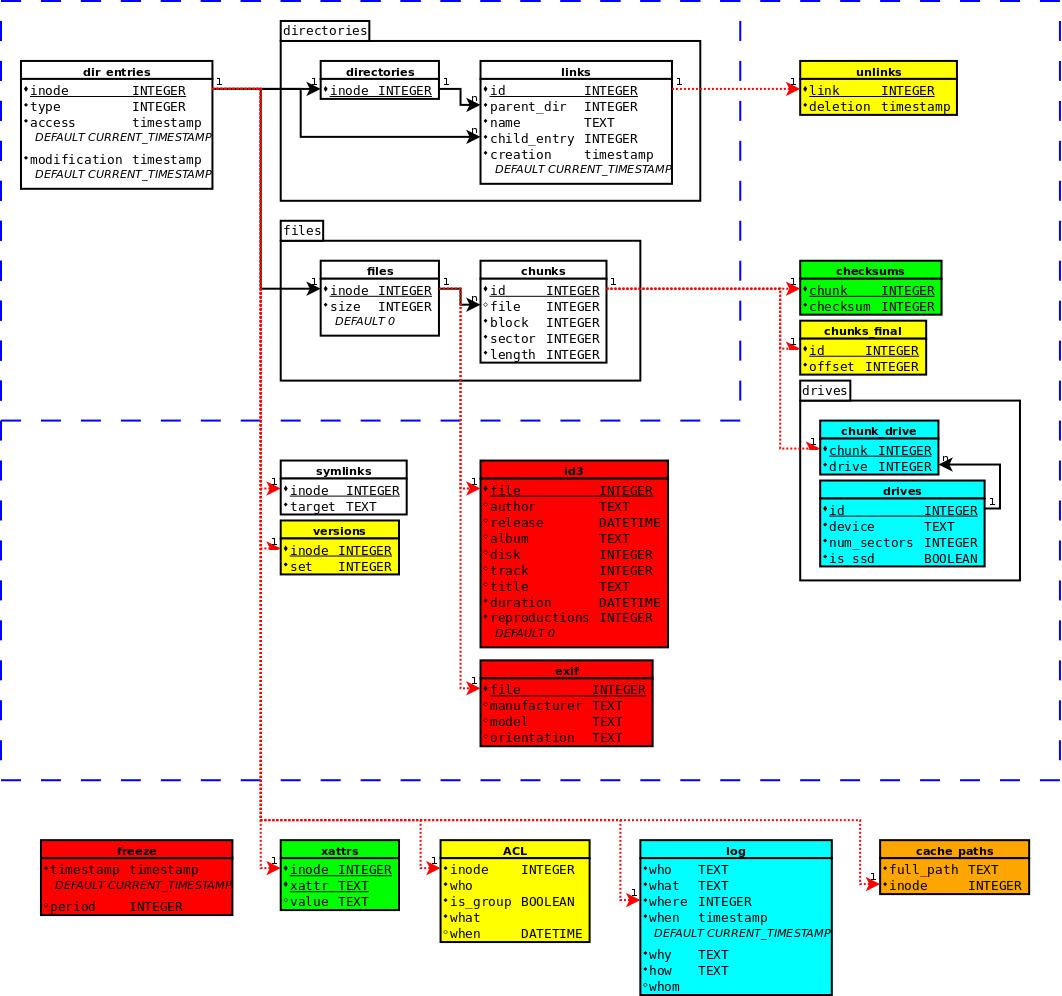
Como habréis podido ver hace días que no escribo por aquí y sin embargo en el svn ha habido muchos cambios... Esto es debido por un lado a que las modificaciones en el core para que acepte el lanzamiento de eventos para los plugins esta siendo mas complicado de lo que parecía debido a que hay que pensar en como aislar correctamente cada una de las partes (hasta ahora no tenia problemas, pero el plugin de checksums funciona a muy bajo nivel y además recibe eventos de distintas partes del código). Sin embargo estos replanteamientos están permitiendo una mayor independencia entre cada una de las partes y además me esta permitiendo el optimizar y documentar código bastante antiguo (en concreto estoy rompiéndome la cabeza para que DB.truncate utilice por debajo a DB.Split_Chunks), así que estoy matando tres pájaros de un tiro :-)Pero por otro lado también he estado aprovechando el tiempo, y el sistema de plugins ya esta bastante maduro. El sistema me ha quedado bastante escueto y portable, por lo que se podría utilizar en otros sistemas que precisen de un sistema de plugins, pero aunque ya haya otros sistemas de plugins para python (y algunos ya se me han adelantado en la idea de convertirlos en sistema "oficial") lo cierto es que no he visto ninguno que tenga algún mecanismo de control de dependencias entre plugins, y aunque creía que iba a ser mas complicado lo cierto es que al final ha sido casi obvio: al cargar el modulo obtenemos las clases de los plugins y vemos cuales son sus dependencias. Si no están todas disponibles dejamos el plugin pendiente, y si lo están entonces lo cargamos y comprobamos entre los pendientes si para alguno de ellos ha cambiado la situación. Simple, fácil y para toda la familia :-DEs por esto por lo que todavía no le estoy dando mucha popularidad al sistema ya que quiero tenerlo bien fino antes de abrirlo al publico (sobretodo por el tema de los plugins que se meten muy adentro del funcionamiento del sistema), pero probablemente para la versión 0.3 ya haga un llamamiento publico buscando ideas y colaboradores (y si, prometo que intentare poner al día y en la web cuales son los checkpoints para cada versión...). Sin embargo precisamente por esto he estado actualizando (y limpiando) el diagrama de la estructura de tablas mas acorde a como se esta perfilando el sistema ahora que empiezan a funcionar los plugins (mi idea era implementarlo después de la versión 1.0, pero con motivo del concurso y de la "participación de la comunidad" he tenido que cambiar las fechas para hacerlo mas accesible) y este es el resultado:(Los colorines son para indicar la dificultad de implementar cada uno de los modulos según cuanto haya que modificar el código: blanco=implementado, verde=directo o casi directo, amarillo=alguna modificación, naranja=reimplementación en parte, rojo=reimplementación de gran parte y turquesa=implementado pero necesita mejoras. Obviamente, con los checksums me equivoque...)Como podéis ver, arriba a la izquierda tenemos el core, ya implementado. He agrupado lo que correspondería al plugin de directorios y al de archivos porque aunque por el momento no tenga pensado implementarlos como modulos externos, lo cierto es que cada vez me esta tentando mas la idea (¡Mama mama, sin directorios! ¡Mama mama, sin archivos! ¡Mama mama, sin datos! X-D). Luego en el siguiente nivel tenemos los modulos de implementación que como dije anteriormente son dependientes de los elementos del core, y por ultimo tenemos los de valor añadido, en los cuales he puesto el ACL y el log (antes los tenia como de implementación) debido a que no son dependientes directos del core. También tengo aquí a un nuevo vecino en el barrio, xattrs (atributos extendidos), que aunque si es dependiente del core lo cierto es que no depende de sus claves únicas. Además, realmente voy a implementar los atributos extendidos para completar la funcionalidad del sistema de archivos y porque va a ser igual de sencillo que los symlinks (al igual que estos, se podría hacer con un mapeo directo de funciones) ya que a titulo personal, me parece una solución mucho mejor el usar algún tipo de estructura como las tablas id3 y exif, no un simple clave-valor que no da ninguna idea de cuales datos faltan por rellenar (lo admito, estoy obsesionado con los tags de los mp3s en el iTunes hasta el punto de que no solo relleno todos los campos de autor/album/disco/pista/titulo para tenerlos bien organizados sino que le meto dentro a los archivos todas las imágenes del album e incluso la letra de las canciones... :-P). Sin embargo también tengo que reconocer que aunque no son muy usados (al menos son unos completos desconocidos para el usuario medio, y para mi hasta hace poco), realmente pueden ser muy potentes y en un sistema de archivos "tradicional" puede ser usado para implementar un ACL y aumentar el nivel de seguridad, por ejemplo. En cualquier caso, para todo lo que se pueden usar los atributos extendidos un sistema dedicado puede cumplir su tarea mucho mejor, pero las estructuras en los sistemas de archivos tradicionales son demasiado fijas como para añadir este tipo de funcionalidades. Por eso la flexibilidad que ofrecen las bases de datos en estos casos es justo una de las razones que me impulsaron a usar una como base para diseñar el sistema de archivos.Pero este pequeño by-pass con replanteamiento de puntos de vista incluido también me esta permitiendo el tener tiempo para pensar sobre nuevos modulos, plugins y funciones que añadir al sistema, y parte del merito se lo tengo que dar a mi buena amiga Jennifer, una completa n00b para estas cosas (bastante que la conseguí sacar del lado oscuro y que empezara a usar Linux... :-P) pero que sin embargo su punto de vista como usuario raso me ha sido bastante útil (¡gracias! :-D ).Una de las ideas que me dio fue el implementar algún sistema de búsqueda avanzada en situaciones limite, del estilo "he buscado la foto del garito aquel en la playa en que estuve desfasando con mis amigas en la que salia guapísima, pero no me acuerdo si es de este año o del anterior y no se si las he borrado o que porque no las encuentro" (nota: aunque no haya dicho nada, casi desde que empecé el proyecto en el diagrama arriba a la derecha hay un modulito muy majo llamado "unlinks"... Si, he pensado en todo, también en otro llamado "purge" que no sale ;-) ). "Además, no quiero que salgan las fotos del tío con el que me enrolle esa noche no sea que entre mi novia en un momento inoportuno cuando este buscando la foto" (a esto ultimo lo llamo yo "ganas de fastidiarme", solo que no con estas palabras...). Al leer esto algunos pensaran que eso es imposible, y otros pensaran que quizás SpotLight o Beagle ya lo hacen (realmente esta idea suya les correspondería mas a unas aplicaciones de alto nivel como ellos que a un sistema de archivos, pero un poco de ayuda por debajo les facilitaría mucho la tarea al igual de lo que podría ocurrir si combinásemos ZFS con TimeMachine... :-) ). Lo cierto es que SpotLight es buenísimo (Beagle nunca lo he usado porque siempre lo desinstalaba ya que mis maquinas con Linux nunca han sido lo suficientemente potentes como para encima tener un proceso accediendo al disco todo el rato...) pero nunca he visto que llegara a un nivel de precisión quirúrgica tan avanzado (quizás lanzandolo desde linea de comandos y procesando una consulta muy elaborada, pero si fuera así de fácil habría un montón de artículos escritos en internet al respecto y lo cierto es que no he oído nada). Yo tengo que ser sincero: es muy complicado, pero no imposible. Aquí el mayor problema depende de la adquisición de los metadatos (día-noche, fechas contextualizadas, reconocimiento de caras...) pero si se tienen y están bien organizados, el problema se reduciría a una simple búsqueda en la base de datos. No diré que lo vaya a implementar... pero si que lo tendré en cuenta para orientar posibles mejoras futuras.Otras ideas que surgieron entre los dos fueron la eliminación segura de archivos (que ya lo tenia pensado antes pero me gusto ver que no soy el único preocupado :-) ) o la compactación de los archivos (quizás para mas adelante, ya hay suficiente lío con la escritura de los chunks como para encima meter esto). Sin embargo al ver todo lo que esta creciendo el sistema me esta entrando una pequeña duda: ¿y si SQLite no es lo suficientemente potente como para moverlo todo? SQLite es un motor de bases de datos muy optimizado, pero tiene el inconveniente de que cuando se accede a el bloque la base de datos entera, y con tanta funcionalidad añadida a falta de pruebas de rendimiento un sistema que ponga a funcionar muchos modulos podría tener problemas... Una solución bastante practica podría ser el que los modulos en lugar de crear sus tablas en la base de datos principal las creen en bases de datos secundarias, con lo que aparte de aumentar la modularización permitirá el acceder en paralelo a las distintas tablas (sobretodo con equipos multicore como los que se venden hoy día) y además se evitaría el meter "mierda" en la base de datos principal y la desinstalación de modulos seria mas sencilla, sin embargo la adaptación a un sistema autocontenido se complicaría sobremanera. Bien es cierto que todavía queda mucho para entonces, pero siempre es bueno planear tus actos con dos o tres pasos de antelación... :-D Por el momento lo dejo aquí anotado como recordatorio para el futuro ;-)
3 Octubre, 2010
Planificación: Estructura de JavaDiKt
En esta entrada esbozaremos de manera simple como funcionará la estructura interna de JavaDiKt y, por consiguiente, como será la planificación del desarrollo del programa en función de esta estructura.
JavaDiKt es un programa complicado, al menos lo más complicado a lo que me he enfrentado nunca en lo que a desarrollo se refiere. Desde que aprendí a programar en C hace 4 años más o menos y en Java después, he hecho algunos programas, pero ninguno que se parezca a este. La mayoría de ellas eran pequeños y de poca utilidad, siempre por consola. Según los objetivos marcados en la entrada ¿Qué es JavaDiKt?, el programa plantea una serie de problemas de programación nuevos para mí:
- Implementación de un manejador de una base de datos
- Desarrollo de una interfaz gráfica interactiva(GUI)
- Desarrollo de un sistema de comunicación entre la base de datos y la interfaz gráfica
- Planificación exhaustiva y detallada del proyecto
- Elaboración de documentación útil y clara
- Cuidado a la hora de elegir licenciamiento del proyecto y de las herramientas y librerías
- Cuidado del rendimiento del programa
- Mantenimiento de código comprensible
- Pruebas de rendimiento y funcionamiento
- Mantenimiento de recursos web
Estuve pensando un buen rato en todo esto, abrumado porque no sabía por donde empezar. Finalmente, me puse la careta de ingeniero y pensé que para empezar lo mejor era tomar la estrategia más evidente: la división en subproblemas.
Me dí cuenta de que los problemas podían dividirse en varios tipos:
- Problemas generales: son aquellos que nos acompañan en toda o prácticamente toda la fase de desarrollo, en este caso, se van solucionando poco a poco a medida que va aumentando el código. De la lista anterior, serían la elaboración de documentación, el cuidado del rendimiento, el mantenimiento del código y el mantenimiento de los recursos web.
- Problemas específicos: son problemas que ocurren únicamente en una fase del periodo de desarrollo, y que, una vez terminada no vuelven a aparecer. De los mencionados anteriormente, serían el licenciamiento, la planificación, el manejo de la base de datos, el desarrollo de la GUI y la comunicación entre ambas.
Por lo tanto, no se puede hacer una planificación de los problemas generales, pero si de los específicos. De hecho, los problemas específicos requieren de un orden especial mientras que los problemas generales están implícitos en cada uno de los problemas específicos. Decidí entonces que debía solucionar los problemas generales a medida que eran necesarios para solucionar los específicos, y ordené estos últimos de forma que conformaban una lista secuencial de tareas:
- Cuidado a la hora de elegir licenciamiento del proyecto y de las herramientas y librerías
- Planificación exhaustiva y detallada del proyecto
- Implementación de un manejador de una base de datos
- Desarrollo de una interfaz gráfica interactiva(GUI)
- Desarrollo de un sistema de comunicación entre la base de datos y la interfaz gráfica
El primero de los problemas lo solucioné rápidamente eligiendo la GPLv3 para el programa y comprobando que el resto de material que quería usar era compatible con esta licencia. El segundo problema, la planificación, definiría como se iban a realizar los siguientes tres pasos, que eran los problemas reales de programación. Decidí entonces, dado que eran tres problemas, que el programa constaría de tres estratos: la capa de datos, encargada de gestionar la base de datos, la capa de GUI, encargada de interactuar con el usuario y la capa de core, encargada de comunicar ambas entre sí y de gestionar su arranque y funcionamiento. La capa GUI sería la más cercana al usuario y la de datos la más lejana, con core entre las dos.
Se que estoy reinventando la rueda, pero realmente tuve que pensar en todo esto porque nunca había afrontado este tipo de problemas. Creo que esta es la forma intuitiva, simple y elegante de establecer la estructura del programa, y me jugaría el cuello a que el 99% de las personas que han desarrollado alguna aplicación de escritorio han seguido fundamentalmente este esquema.
A partir de aquí empecé ya a pensar en la forma de llevar esta idea a cabo en Java, y llegué a la conclusión de lo mejor era dividir el programa en cuatro paquetes, data, core, GUI y tools. Éste último paquete contendría todas aquellas utilidades necesarias para el desarrollo del programa pero que nunca serían incluidas en una versión final, como pueden ser las clases de prueba o las herramientas para construir la base de datos por primera vez. La estructura queda entonces así:
Que es un dibujo muy tonto pero creo que muy explicativo.
Con esto terminamos la entrada de hoy, en la próxima hablaremos sobre el paquete data y su planificación.
3 Octubre, 2010
Lista inicial de funcionalidades
La lista inicial de funcionalidades, ordenada por importancia, es la siguiente:
1. Reconocimiento de opciones introducidas por línea de comandos.
2. Previsualización de un archivo individual introducido por línea de comandos
junto al nombre del ejecutable.
3. Previsualización de un número de archivos indefinido introducidos por línea de comandos junto al nombre del ejecutable.
4. Subshell con reconocimiento de comandos de cambio de directorio.
5. Creación de vistas preliminares en base al tipo del archivo.
6. Mostrado de vistas preliminares cuando se realice un cambio de directorio.
7. Control del panel de previsualización mediante comandos de teclado.
8. Configuración del entorno de previsualizado mediante línea de comandos y archivos de configuración.
9. Persistencia en las opciones de configuración.
10. Selección de archivos del panel mediante el ratón y ejecución de acciones sobre ellos mediante línea de comandos.
11. Panel complementario para la previsualización de directorios en tiempo real mientras se introduce su nombre por línea de comandos.
3 Octubre, 2010
Conceptos básicos del juego
La mayor complejidad del juego a nivel de desarrollo es detectar el trazado que hace el ratón y analizar si el recorrido que ha hecho es el apropiado para hacer aterrizar un avión.
Trazado de la ruta del ratón
Esta parte es la más sencilla. Durante el tracking, en cada iteración del game loop, se captura la posición del ratón. Si esa posición está demasiado alejada de la anterior posición leída, se interpolan los puntos entre ambas posiciones. Con esto, ya tenemos un conjunto de puntos con la ruta que ha seguido el ratón.
Detección de la ruta a través de la pista de aterrizaje
Un trazado o ruta será correcta siempre y cuando pase en orden por una serie de zonas ordenadas colocadas al principio de las pistas de aterrizaje, de modo que si el algoritmo detecta que pasa por la zona 1, y luego por la zona 2, entonces es que ha seguido el camino correcto.
Para llevar a cabo esta labor, seguimos el siguiente proceso sobre la ruta trazada por el ratón:
- Para cada punto en la ruta, vemos en qué zona está: puede estar en alguna de las zonas de aterrizaje, o fuera de toda zona (representado con -1). El problema de detectar si está en una zona lo abordaremos más abajo. Tras este paso, tendremos un vector de zonas con enteros que referencian a cada una de las zonas por las que han pasado los puntos
- Seguidamente, agrupamos los puntos que estén en las mismas zonas. Es decir, si en el vector de zonas tenemos: [-1, -1, -1, 0, 0, 0, 1, 1, 1], lo convertiremos a [-1, 0, 1]. Así, el procesado es más sencillo, ya que lo que realmente nos interesa es saber el orden en el que los puntos han pasado por las zonas.
- Tras ello aislamos el último grupo de puntos que esté dentro de una zona de aterrizaje, es decir, si tenemos [-1, -1, 0, -1, 0, 1, -1], nos quedaríamos con [0,1], ya que descartamos los puntos que estén fuera de cualquier zona y nos quedamos con el último grupo de puntos en zona.
- Finalmente, tenemos un vector con las zonas ordenadas, simplemente tenemos que comprobar que las zonas se suceden en el orden correcto, caso en que la ruta será correcta.
Contención de un punto en una zona
Inicialmente pensé en que las zonas podrían ser rectangulares. La detección de un punto en una zona rectangular es trivial. Pero al final eso me iba a impedir poner, por ejemplo, pistas en diagonal, así que he tenido que ver cómo detectar si un punto se encuentra en una zona poligonal definida según sus puntos. Según he ido investigando, parece ser un problema bastante común conocido como point in polygon, y que ofrece multitud de posibles soluciones, principalmente dependiendo de la complejidad de los polígonos.
En mi caso, al tratarse de polígonos convexos y cerrados (sin agujeros dentro), opté por implementar el ray casting algorithm: dando un polígono y un punto, se traza una línea (un rayo) desde fuera del polígono hasta el punto. Si el rayo cruza un número PAR de veces el polígono, entonces el punto estará fuera, mientras que si el rayo cruza el polígono un número IMPAR de veces, entonces el punto estará dentro de la figura.
Los polígonos están implementados como un conjunto de aristas (segmentos), que a su vez se componen de dos puntos cada una. Así, el algoritmo genera un rayo desde una posición arbitraria, fuera de la región, hasta el punto, y comprueba si ese rayo y cada uno de los segmentos del polígono se cruzan, llevando un contador. El algoritmo para calcular la intersección lo he cogido de este post de stackOverflow.
Y eso es todo. Si queréis echarle un vistazo, hay un ejemplo en el SVN, en la carpeta branches/regionDetection.
Saludos.
2 Octubre, 2010
04. Casos de uso
En el siguiente documento, pretendo hacer un análisis de los casos de uso de YakiTo. Para ello, en primer lugar muestro un diagrama general de los principales casos de uso de la aplicación, para después realizar un análisis detallado de cada caso de uso en particular.
2 Octubre, 2010
Metodología de desarrollo
Considerando que el desarrollo del proyecto lo voy a realizar de forma individual, la elección de una metodología de desarrollo “pesada” podría llevar más trabajo del necesario para coordinar a .. un programador. En realidad, la intención es utilizar una metodología que permita la adaptación a cambios rápidos en los requisitos e incorporar nuevas funcionalidades de forma fácil y sin necesidad de llevar a cabo una reestructuración completa del proyecto.
Con esta premisa, he estado investigando sobre diferentes metodologías de las llamadas “ágiles”. El adjetivo que las califica ya dice bastante de ellas. Sin embargo, englobadas en esa categoría se encuentran muchas y muy variadas, aunque todas ellas mantengan una base común. Por su frecuencia de utilización y su importancia, he reducido el abánico de posibilidades a únicamente 3: Scrum, eXtreme Programming y Test-Driven Development.
De las 3 candidatas, me decidido por utilizar la tercera, Test-Driven Development o Desarrollo guiado por pruebas. Cada ciclo de desarrollo se compone de los siguientes pasos:
- Se elige una funcionalidad que esté pendiente de implementar
- Se escribe un test que ponga a prueba el funcionamiento de dicha funcionalidad
- Se comprueba que el test falla para el código existente actualmente
- Se implementa el código estrictamente necesario para pasar la prueba, sin necesidad de tener en cuenta futuras ampliaciones o modificaciones
- Se ejecutan todos los tests: el escrito al comienzo del ciclo y los de ciclos anteriores, comprobando que todo funciona correctamente
- Se refina el código escrito, teniendo en cuenta que el código siga pasando los tests
- Se actualiza la lista de funcionalidades pendientes, borrando la ya implementada u otras que hayan sido abarcadas por esta e introduciendo nuevas posibles funcionalidades detectadas durante el último ciclo
Del ciclo de desarrollo se desprende la necesidad de crear una lista inicial de funcionalidades pendientes de ser desarrolladas, la cual será la primera “piedra” de este proyecto. Dedicaré la próxima entrada del blog al diseño de la lista y la elección de la primera funcionalidad a implementar en el ciclo #1 del desarrollo.
29 Septiembre, 2010
Personaje moviendose
Buenas, enlazo a un video que olvide comentar en el blog:Ahora el personaje se mueve por la pantalla donde aparecen unos bloques y un suelo. Se han añadido luces y sombras.Ver videoYa va pareciendo un juego. El siguiente paso, probar la fisica. Espero que os guste, saludos!
29 Septiembre, 2010
Reabiertas las encuestas
29 Septiembre, 2010
Diseño del protagonista
Buenas a tod@s.Este es el diseño 3D del personaje principal del juego. Aun no tiene nombre. Espero que os guste. Ya iré añadiendo más imágenes y animaciones.Podeis opinar aquí y en la encuesta que aparece a la izquierda.¡Saludos!
Colabora









{kind=link}
{kind=link}